#1. Kubernetes에서 Horizontal Pod Autoscaler (HPA)란?
애플리케이션의 수요에 따라 자동으로 파드 인스턴스 수를 조정하는 기능을 제공합니다. 이는 클러스터 내에서 애플리케이션의 부하가 증가하거나 감소할 때 자동으로 스케일링되어 리소스를 효율적으로 활용할 수 있도록 합니다.
HPA는 리소스 사용률 또는 기타 지표를 모니터링하고, 정의된 임계값을 초과하거나 미달할 때 파드의 수를 조정합니다. 이를 통해 애플리케이션의 가용성을 유지하면서도 리소스 사용량을 최적화할 수 있습니다.
일반적으로 HPA는 다음 단계를 따릅니다:
지표(Metrics) 수집: HPA는 애플리케이션의 수요를 측정하기 위해 리소스 사용률(CPU, 메모리 등) 또는 사용자 지정 메트릭을 사용합니다.
스케일링 조건 설정: 사용자는 HPA를 통해 애플리케이션을 어떻게 스케일링할지 정의합니다. 예를 들어, CPU 사용률이 특정 임계값을 초과하면 파드 인스턴스 수를 증가시킬 수 있습니다.
자동 스케일링: 설정된 조건이 충족되면 HPA는 자동으로 파드의 수를 조정하여 애플리케이션의 수요를 충족시킵니다.
스케일링 조정: 수요가 줄어들면 HPA는 더 적은 수의 파드 인스턴스를 유지할 수 있도록 파드의 수를 감소시킵니다.
이러한 과정을 통해 Kubernetes는 애플리케이션을 실행하는 데 필요한 최소한의 리소스만을 할당하여 클러스터의 사용률을 최적화하고, 애플리케이션의 가용성을 보장합니다.
# Run and expose php-apache server
curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml
cat php-apache.yaml | yh
kubectl apply -f php-apache.yaml
# 확인
kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
...
# 모니터링 : 터미널2개 사용
watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
kubectl exec -it deploy/php-apache -- top
# 접속
PODIP=$(kubectl get pod -l run=php-apache -o jsonpath={.items[0].status.podIP})
curl -s $PODIP; echo

HPA 생성 및 부하 발생 후 오토 스케일링 테스트 : 증가 시 기본 대기 시간(30초), 감소 시 기본 대기 시간(5분) → 조정 가능
# Create the HorizontalPodAutoscaler : requests.cpu=200m - 알고리즘
# Since each pod requests 200 milli-cores by kubectl run, this means an average CPU usage of 100 milli-cores.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl describe hpa
...
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
...
# HPA 설정 확인
kubectl get hpa php-apache -o yaml | kubectl neat | yh
spec:
minReplicas: 1 # [4] 또는 최소 1개까지 줄어들 수도 있습니다
maxReplicas: 10 # [3] 포드를 최대 5개까지 늘립니다
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache # [1] php-apache 의 자원 사용량에서
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # [2] CPU 활용률이 50% 이상인 경우
# 반복 접속 1 (파드1 IP로 접속) >> 증가 확인 후 중지
while true;do curl -s $PODIP; sleep 0.5; done
# 반복 접속 2 (서비스명 도메인으로 파드들 분산 접속) >> 증가 확인(몇개까지 증가되는가? 그 이유는?) 후 중지 >> 중지 5분 후 파드 갯수 감소 확인
# Run this in a separate terminal
# so that the load generation continues and you can carry on with the rest of the steps
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
- 오브젝트 삭제: kubectl delete deploy,svc,hpa,pod --all
KEDA (Kubernetes-based Event Driven Autoscaler)란?
이벤트 기반의 워크로드를 자동으로 확장하고 축소하는 기능을 제공하는 프로젝트입니다. 주로 이벤트 기반 마이크로서비스 아키텍처를 구축하는 경우 사용됩니다.
KEDA는 Kubernetes의 확장성과 유연성을 활용하여 서버리스 및 이벤트 기반 워크로드에 대한 자동 스케일링을 달성하는 데 중점을 둡니다. 주요 특징 및 작동 방식은 다음과 같습니다:
이벤트 기반 스케일링: KEDA는 이벤트 소스에서 발생하는 이벤트를 모니터링하고, 이벤트의 발생에 따라 워크로드를 확장하거나 축소합니다. 이벤트 소스로는 Kafka, RabbitMQ, Azure 큐 서비스 등 다양한 메시징 시스템이 지원됩니다.
메트릭 기반 스케일링: KEDA는 사용자가 정의한 사용자 지정 메트릭 또는 시스템 리소스(CPU, 메모리 등) 사용률과 같은 기본 메트릭에 기반하여도 스케일링할 수 있습니다.
다양한 워크로드 지원: KEDA는 다양한 워크로드 유형에 대한 스케일링을 지원합니다. HTTP 요청, 메시지 큐 메시지, 레코드 등 다양한 이벤트 유형을 처리할 수 있습니다.
Kubernetes 네이티브: KEDA는 네이티브 Kubernetes CRD(Custom Resource Definition) 및 컨트롤러로 구현되어 Kubernetes 클러스터 내에서 간편하게 배포하고 관리할 수 있습니다.
KEDA를 사용하면 이벤트 기반 애플리케이션의 부하에 따라 자동으로 스케일링되므로, 리소스를 효율적으로 활용하면서도 애플리케이션의 가용성을 유지할 수 있습니다. 이는 서버리스 및 이벤트 기반 아키텍처를 구축하는 데 매우 유용한 기능입니다.
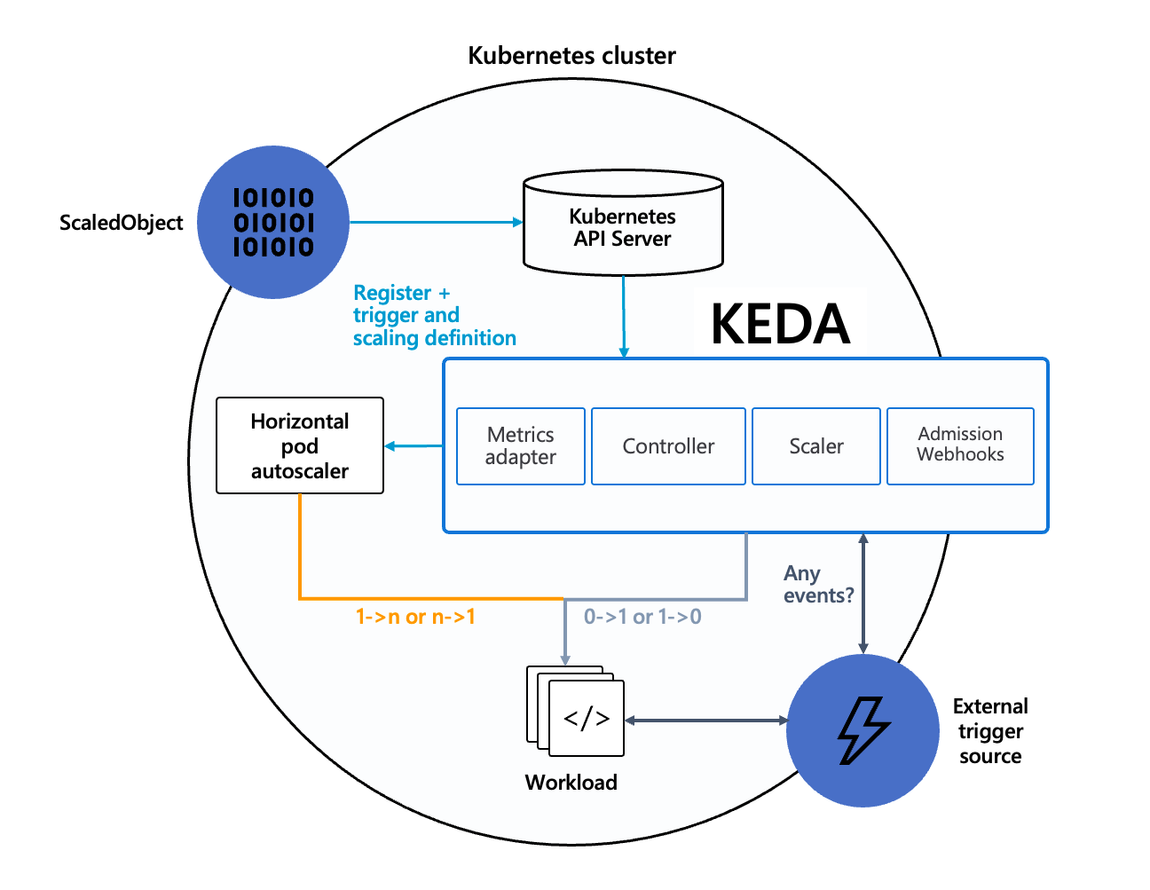
기존의 HPA(Horizontal Pod Autoscaler)는 리소스(CPU, Memory) 메트릭을 기반으로 스케일 여부를 결정하게 됩니다.
반면에 KEDA는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다.
예를 들어 airflow는 metadb를 통해 현재 실행 중이거나 대기 중인 task가 얼마나 존재하는지 알 수 있습니다.
이러한 이벤트를 활용하여 worker의 scale을 결정한다면 queue에 task가 많이 추가되는 시점에 더 빠르게 확장할 수 있습니다.
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.svc:9092 # Comma separated list of Kafka brokers “hostname:port” to connect to for bootstrap.
consumerGroup: my-group # Name of the consumer group used for checking the offset on the topic and processing the related lag.
topic: test-topic # Name of the topic on which processing the offset lag. (Optional, see note below)
lagThreshold: '5' # Average target value to trigger scaling actions. (Default: 5, Optional)
offsetResetPolicy: latest # The offset reset policy for the consumer. (Values: latest, earliest, Default: latest, Optional)
allowIdleConsumers: false # When set to true, the number of replicas can exceed the number of partitions on a topic, allowing for idle consumers. (Default: false, Optional)
scaleToZeroOnInvalidOffset: false
version: 1.0.0 # Version of your Kafka brokers. See samara version (Default: 1.0.0, Optional)

# KEDA 설치
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
kubectl create namespace keda
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --version 2.13.0 --namespace keda -f keda-values.yaml
# KEDA 설치 확인
kubectl get all -n keda
kubectl get validatingwebhookconfigurations keda-admission
kubectl get validatingwebhookconfigurations keda-admission | kubectl neat | yh
kubectl get crd | grep keda
# keda 네임스페이스에 디플로이먼트 생성
kubectl apply -f php-apache.yaml -n keda
kubectl get pod -n keda
# ScaledObject 정책 생성 : cron
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2
pollingInterval: 30
cooldownPeriod: 300
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
kubectl apply -f keda-cron.yaml -n keda
# 그라파나 대시보드 추가
# 모니터링
watch -d 'kubectl get ScaledObject,hpa,pod -n keda'
kubectl get ScaledObject -w
# 확인
kubectl get ScaledObject,hpa,pod -n keda
kubectl get hpa -o jsonpath={.items[0].spec} -n keda | jq
...
"metrics": [
{
"external": {
"metric": {
"name": "s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx",
"selector": {
"matchLabels": {
"scaledobject.keda.sh/name": "php-apache-cron-scaled"
}
}
},
"target": {
"averageValue": "1",
"type": "AverageValue"
}
},
"type": "External"
}
# KEDA 및 deployment 등 삭제
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda
# KEDA 및 deployment 등 삭제
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda kubectl delete namespace keda
#3. Vertical Pod Autoscaler(VPA)란
Kubernetes 클러스터에서 애플리케이션의 리소스 요구량을 동적으로 조정하여 성능을 최적화하는 기능을 제공합니다. HPA(Horizontal Pod Autoscaler)가 파드 인스턴스의 수를 조정하여 수평으로 스케일링하는 데 비해, VPA는 파드의 개별 인스턴스에 할당된 리소스(예: CPU, 메모리)를 조정하여 수직으로 스케일링합니다.
일반적으로 Kubernetes 클러스터에서는 파드를 시작할 때 정적으로 리소스를 할당합니다. 그러나 실제 애플리케이션의 요구에 따라 리소스 요구량은 변할 수 있습니다. 예를 들어, 애플리케이션의 부하가 증가하면 추가 리소스가 필요할 수 있습니다. VPA는 이러한 동적인 요구에 대응하여 파드의 리소스 할당을 조정하여 애플리케이션의 성능을 향상시킵니다.
VPA는 다음과 같은 주요 원칙에 기반합니다:
모니터링: VPA는 파드의 동작을 모니터링하고 리소스 사용량을 추적합니다.
분석: 수집된 데이터를 분석하여 애플리케이션의 리소스 요구량을 결정합니다.
자동 조정: 정의된 정책에 따라 VPA는 파드의 리소스 요구량을 동적으로 조정합니다. 이는 파드를 다시 시작하지 않고도 이루어집니다.
통합: VPA는 Kubernetes API와 통합되어 관리되며, 사용자가 설정하고 모니터링할 수 있습니다.
VPA를 사용하면 애플리케이션의 리소스 사용을 최적화하여 클러스터의 효율성을 향상시킬 수 있습니다. 또한 잘못된 리소스 할당으로 인한 성능 저하를 방지하고, 비용을 절감할 수 있습니다.

kube_customresource_vpa_containerrecommendations_target{resource="cpu"}
kube_customresource_vpa_containerrecommendations_target{resource="memory"}

# 코드 다운로드
git clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
tree hack
# openssl 버전 확인
openssl version
OpenSSL 1.0.2k-fips 26 Jan 2017
# openssl 1.1.1 이상 버전 확인
yum install openssl11 -y
openssl11 version
OpenSSL 1.1.1g FIPS 21 Apr 2020
# 스크립트파일내에 openssl11 수정
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# Deploy the Vertical Pod Autoscaler to your cluster with the following command.
watch -d kubectl get pod -n kube-system
cat hack/vpa-up.sh
./hack/vpa-up.sh
kubectl get crd | grep autoscaling
kubectl get mutatingwebhookconfigurations vpa-webhook-config
kubectl get mutatingwebhookconfigurations vpa-webhook-config -o json | jq
# 모니터링
watch -d "kubectl top pod;echo "----------------------";kubectl describe pod | grep Requests: -A2"
# 공식 예제 배포
cd ~/autoscaler/vertical-pod-autoscaler/
cat examples/hamster.yaml | yh
kubectl apply -f examples/hamster.yaml && kubectl get vpa -w
# 파드 리소스 Requestes 확인
kubectl describe pod | grep Requests: -A2
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 587m
memory: 262144k
--
Requests:
cpu: 587m
memory: 262144k
# VPA에 의해 기존 파드 삭제되고 신규 파드가 생성됨
kubectl get events --sort-by=".metadata.creationTimestamp" | grep VPA
2m16s Normal EvictedByVPA pod/hamster-5bccbb88c6-s6jkp Pod was evicted by VPA Updater to apply resource recommendation.
76s Normal EvictedByVPA pod/hamster-5bccbb88c6-jc6gq Pod was evicted by VPA Updater to apply resource recommendation.
- 삭제: kubectl delete -f examples/hamster.yaml && cd ~/autoscaler/vertical-pod-autoscaler/ && **./hack/vpa-down.sh**
#4. Cluster Autoscaler(CA)란
Kubernetes 클러스터에서 노드 수를 동적으로 조정하여 리소스 수요에 따라 클러스터를 확장하거나 축소하는 기능을 제공합니다. 이는 클러스터 내에서 애플리케이션의 부하가 증가하거나 감소할 때 자동으로 노드를 추가하거나 제거함으로써 클러스터의 확장성을 향상시킵니다.
CA의 주요 작동 원리는 다음과 같습니다:
노드 수요 모니터링: CA는 클러스터 내의 파드 및 노드의 상태를 지속적으로 모니터링하여 현재 리소스 사용량 및 파드의 스케줄링 상태를 파악합니다.
노드 확장/축소: 만약 클러스터 내에서 파드가 스케줄링되지 못하거나 리소스 부족 상태가 발견되면, CA는 클라우드 프로바이더(API를 통해) 또는 온프레미스 인프라에서 추가 노드를 프로비저닝하고 클러스터에 연결합니다. 반대로, 노드에 빈 자원이 많을 경우 CA는 사용되지 않는 노드를 제거하여 클러스터의 크기를 줄입니다.
파드 이동: 노드가 추가되거나 제거될 때, CA는 해당 노드에 있는 파드를 다른 노드로 안전하게 이동시킵니다. 이를 통해 서비스의 가용성을 유지하면서도 클러스터의 크기를 조절할 수 있습니다.
Cluster Autoscaler는 Kubernetes 클러스터를 더욱 유연하고 효율적으로 만들어주는 중요한 기능입니다. 이를 통해 리소스를 최적화하고 애플리케이션의 가용성을 유지하는 데 도움이 됩니다.

- Cluster Autoscale 동작을 하기 위한 cluster-autoscaler 파드(디플로이먼트)를 배치합니다.
- Cluster Autoscaler(CA)**는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다.
- 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용합니다.
# EKS 노드에 이미 아래 tag가 들어가 있음
# k8s.io/cluster-autoscaler/enabled : true
# k8s.io/cluster-autoscaler/myeks : owned
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...

Cluster Autoscaler for AWS provides integration with Auto Scaling groups. It enables users to choose from four different options of deployment:
- One Auto Scaling group
- Multiple Auto Scaling groups
- Auto-Discovery : Auto-Discovery is the preferred method to configure Cluster Autoscaler. Click here for more information.
- Control-plane Node setup
Cluster Autoscaler will attempt to determine the CPU, memory, and GPU resources provided by an Auto Scaling Group based on the instance type specified in its Launch Configuration or Launch Template.
# 현재 autoscaling(ASG) 정보 확인
# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='클러스터이름']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-44c41109-daa3-134c-df0e-0f28c823cb47 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
# MaxSize 6개로 수정
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 확인
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-c2c41e26-6213-a429-9a58-02374389d5c3 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
# 배포 : Deploy the Cluster Autoscaler (CA)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
# 확인
kubectl get pod -n kube-system | grep cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler | grep node-group-auto-discovery
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
# 모니터링
kubectl get nodes -w
while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
# Deploy a Sample App
# We will deploy an sample nginx application as a ReplicaSet of 1 Pod
cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
# Scale our ReplicaSet
# Let’s scale out the replicaset to 15
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# 확인
kubectl get pods -l app=nginx -o wide --watch
kubectl -n kube-system logs -f deployment/cluster-autoscaler
# 노드 자동 증가 확인
kubectl get nodes
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
./eks-node-viewer --resources cpu,memory
혹은
./eks-node-viewer
# 디플로이먼트 삭제
kubectl delete -f nginx.yaml && date
# 노드 갯수 축소 : 기본은 10분 후 scale down 됨, 물론 아래 flag 로 시간 수정 가능 >> 그러니 디플로이먼트 삭제 후 10분 기다리고 나서 보자!
# By default, cluster autoscaler will wait 10 minutes between scale down operations,
# you can adjust this using the --scale-down-delay-after-add, --scale-down-delay-after-delete,
# and --scale-down-delay-after-failure flag.
# E.g. --scale-down-delay-after-add=5m to decrease the scale down delay to 5 minutes after a node has been added.
# 터미널1
watch -d kubectl get node
위 실습 중 디플로이먼트 삭제 후 10분 후 노드 갯수 축소되는 것을 확인 후 아래 삭제를 해보자! >> 만약 바로 아래 CA 삭제 시 워커 노드는 4개 상태가 되어서 수동으로 2대 변경 하자!
kubectl delete -f nginx.yaml
# size 수정
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 3
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
# Cluster Autoscaler 삭제
kubectl delete -f cluster-autoscaler-autodiscover.yaml
'AWS > [AEWS] EKS' 카테고리의 다른 글
| [ AEWS 4주차 ] 정리 (0) | 2024.03.30 |
|---|---|
| [ AEWS 3주차 ] EKS 스토리지 & 노드 그룹 (1) | 2024.03.22 |
| [ AEWS 2주차 ] #2 Service & AWS Loadbalancer Controller & Ingress (1) | 2024.03.15 |
| [ AEWS 2주차 ] #1 EKS VPC CNI란? (0) | 2024.03.12 |
| [ AEWS 1주차 ] #1 EKS란? (0) | 2024.03.08 |